8 Key Insights into Meta's AI-Powered Efficiency Engine at Hyperscale
Meta's infrastructure serves over 3 billion people daily, meaning even a tiny performance blip can waste vast amounts of energy. To tackle this, the company developed a unified AI agent platform that automates both finding and fixing efficiency issues. This article breaks down eight crucial aspects of how these agents work, from the fundamental two-pronged strategy of offense and defense to the tangible power savings achieved. Whether you're an engineer curious about hyperscale optimization or a tech enthusiast, these insights reveal how Meta is turning manual investigation into automated, self-sustaining efficiency at an unprecedented scale.
1. The Hyperscale Efficiency Challenge
At Meta's scale, a 0.1% performance regression in code can translate into megawatts of extra power consumption across the fleet. This isn't just a minor cost—it's a massive operational and environmental concern. Traditional manual approaches to finding and fixing these inefficiencies quickly hit a wall: there simply aren't enough engineers to address every issue. The capacity efficiency program was born to solve this bottleneck, separating the work into two complementary efforts: proactive optimization (offense) and reactive regression mitigation (defense). Without a scalable solution, the team would need to grow headcount proportionally to the expanding infrastructure, which is neither sustainable nor cost-effective.

2. Offense and Defense: The Two Sides of Efficiency
Efficiency at hyperscale isn't a single activity—it's a continuous cycle of two distinct strategies. On the offense side, engineers proactively hunt for optimization opportunities in existing systems, such as rewriting algorithms or tuning configurations to reduce resource usage. On the defense side, teams monitor production to detect regressions—unintended performance hits—that sneak into the codebase. Historically, both sides relied on manual labor: engineers would sift through data, run experiments, and create fixes. But as Meta's infrastructure grew, the sheer volume of issues outpaced human capacity, forcing the innovation of AI-assisted automation.
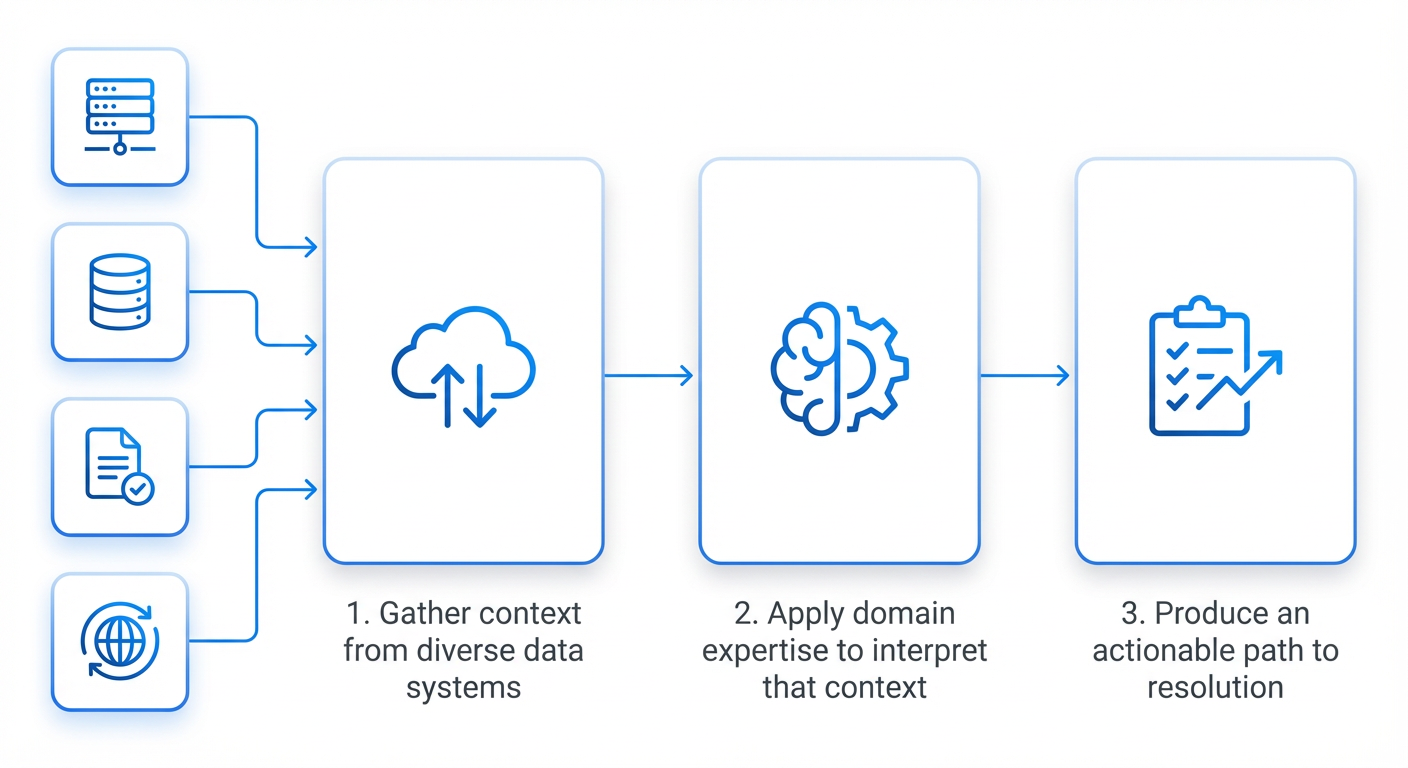
3. The Unified AI Agent Platform
Meta's solution is a unified AI agent platform that captures the domain expertise of senior efficiency engineers. These agents are built from reusable, composable skills—each encoding a specific piece of knowledge (e.g., how to identify a memory leak or analyze CPU utilization). The platform provides a standardized tool interface so agents can query monitoring systems, run simulations, and even deploy fixes. This modular design allows the agents to tackle a wide range of problems without needing to be reprogrammed for each new scenario. It's like having an army of virtual experts that collaborate seamlessly, compressing hours of manual investigation into minutes.
4. FBDetect: Catching Regressions Early
On the defense front, Meta relies on FBDetect, an in-house regression detection tool that catches thousands of performance regressions every week. FBDetect continuously monitors resource usage and flags anomalies. Once a regression is identified, the AI agents spring into action: they automatically root-cause the issue to a specific pull request, assess its impact, and even suggest mitigation strategies. This speed is critical because each hour of delay means more compounding power waste across the fleet. Before AI, engineers might take a full day to diagnose a single regression; now, agents can do it in around 30 minutes.
5. Automated Pull Requests and Resolution
The most advanced agents don't just diagnose—they also fix. For a growing set of common regressions, the AI can automatically generate a ready-to-review pull request that corrects the issue. This bridges the gap between detection and resolution, eliminating the manual steps that often stall progress. For example, an agent might identify an inefficient database query and produce a patch that optimizes it. Engineers then review and approve the changes, but the heavy lifting is already done. This end-to-end automation dramatically increases the throughput of the capacity efficiency program, allowing it to scale power savings without scaling headcount.
6. Scaling Megawatt Delivery Without More People
The core goal of Meta's program is to recover hundreds of megawatts (MW) of power—enough to power hundreds of thousands of American homes for a year. But the team's headcount isn't growing at the same rate. By using AI agents to handle the long tail of efficiency opportunities, Meta can deliver more MW per engineer. The agents work 24/7, never get tired, and can analyze thousands of systems simultaneously. This scalability is the key differentiator: where human teams would be bottlenecked by manual work, the AI platform continuously finds and fixes issues, creating a self-sustaining engine for power savings.
7. The Role of Encoded Domain Expertise
A critical ingredient in these agents is the encoded domain expertise from senior engineers. Rather than relying on generic machine learning, Meta's approach uses explicit knowledge rules and heuristics that have been hardened through years of experience. This knowledge is broken into small, composable skills—like diagnosing high memory usage or detecting CPU throttling—which agents can combine as needed. The result is high-precision automation that avoids false positives and understands the nuances of Meta's unique infrastructure. It's not just about applying AI; it's about marrying AI with deep, practical expertise to make it truly effective.
8. The Future: A Self-Sustaining Efficiency Engine
Meta envisions a future where the capacity efficiency program becomes fully autonomous. The AI agents will not only find and fix issues but also learn from each interaction, continuously improving their skills. As the platform expands to more product areas every half, the volume of automated wins grows. The long-term goal is a system that can predict and prevent regressions before they happen, moving from reactive defense to proactive optimization. This self-sustaining engine would free engineers entirely from repetitive efficiency tasks, allowing them to focus on innovation. It's a blueprint for how hyperscale companies can manage power consumption in an AI-first world.
Meta's unified AI agent platform represents a paradigm shift in how hyperscale efficiency is managed. By automating both offense and defense, the program has already recovered hundreds of megawatts of power and compressed investigation timelines from hours to minutes. The key lessons—encoding domain expertise, using modular skills, and building a unified interface—are applicable far beyond Meta. As AI continues to evolve, such platforms will become essential for any organization grappling with the complexity of massive-scale infrastructure. The ultimate takeaway: when human expertise meets machine automation, even the hardest efficiency problems become solvable at scale.
Related Articles
- Fedora Unveils AI Developer Desktop Initiative: A Local-First Approach for Open Source Development
- VMware Workstation Pro Now Free on Ubuntu 26.04 LTS – A New Era for Linux Virtualization
- Mastering CUBIC Congestion Control: Debugging a Stuck Congestion Window in QUIC
- Fedora Asahi Remix 44 Brings Fedora Linux to Apple Silicon with Enhanced Desktop Experiences
- 10 Critical Insights Into the Copy.Fail Linux Kernel Vulnerability
- How to Join and Make the Most of the Fedora Linux 44 Virtual Release Party
- 6 Key Insights Into Linux Kernel Policy Groups for Smarter Memory Management
- Linux DMA-BUF Subsystem Set for Major Efficiency Boost: User-Space Read/Write Operations on the Horizon