Poetiq's Meta-System Boosts AI Coding Scores Without Model Retraining
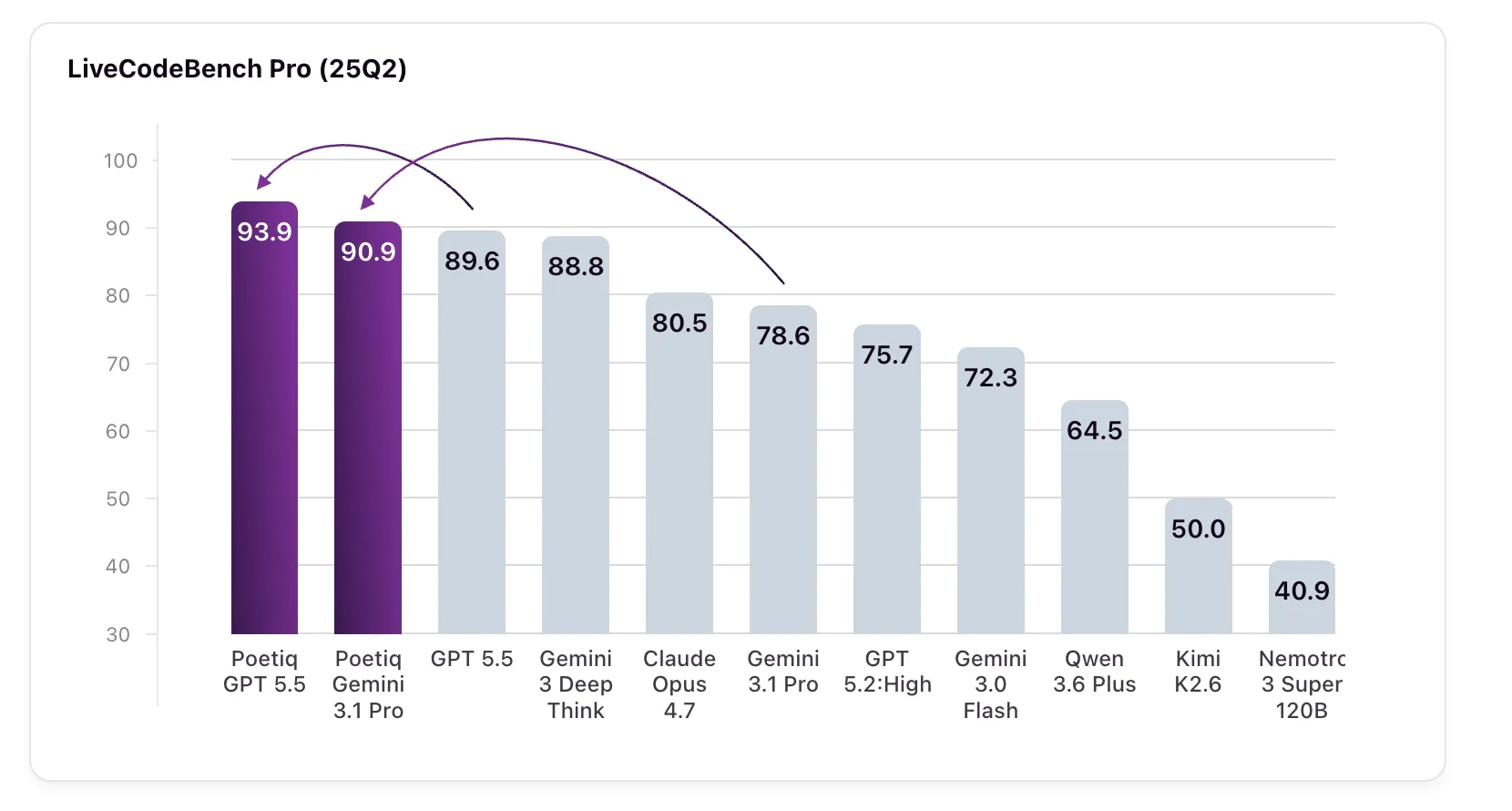
Poetiq recently published remarkable results demonstrating that their Meta-System can automatically construct and optimize an inference harness—without any fine-tuning or internal model access—leading to state-of-the-art performance on the challenging LiveCodeBench Pro (LCB Pro) coding benchmark. This approach improved every large language model tested, including raising GPT 5.5 High from 89.6% to 93.9% and boosting Gemini 3.1 Pro beyond even Google's own specialized model. Below we explore how this system works, why the benchmark matters, and what this means for AI coding.
What is Poetiq's Meta-System and what did it achieve?
Poetiq's Meta-System is an automated framework that designs and optimizes a specialized inference harness—the infrastructure that helps a language model process and respond to coding tasks. By recursively improving this harness based on performance feedback, the system achieves better results without changing the underlying model's weights or architecture. In tests across multiple LLMs, the Meta-System consistently raised scores on LiveCodeBench Pro. For example, GPT 5.5 High jumped from 89.6% to 93.9%, and Gemini 3.1 Pro soared from 78.6% to 90.9%, surpassing Google's Gemini 3 Deep Think (88.8%)—a model not even available via API for independent verification. This proves that a well-designed harness can unlock latent capabilities in any model.
What is LiveCodeBench Pro and why is it important?
LiveCodeBench Pro (LCB Pro) is a competitive coding benchmark designed to resist two common pitfalls: data contamination and overfitting. It sources problems from top competitions, withholds public ground-truth code, and validates solutions against a comprehensive test framework that checks correctness, memory usage, and runtime constraints. Unlike many static benchmarks, LCB Pro receives continuous updates, keeping it relevant. It focuses on C++ challenges and requires creative problem-solving, testing a model's ability to generate high-quality, performant procedural logic. Problems are categorized as Easy, Medium, or Hard based on human solve rates, making it a rigorous measure of AI coding ability that goes beyond simple tool use or bug fixing.
How does Poetiq's approach differ from fine-tuning?
Fine-tuning involves updating a model's weights using additional training data, which can be expensive, time-consuming, and often requires access to model internals. Poetiq's Meta-System takes a different route: it builds and optimizes a harness that sits outside the model. This harness improves how the model processes problems—for instance, by re-prompting, breaking down tasks, or selecting better reasoning paths—without altering the model itself. The result is a model-agnostic boost that can be applied to any LLM, even closed-source ones like GPT or Gemini. This approach is faster, cheaper, and more flexible than fine-tuning, and it achieved significant gains on LCB Pro without any retraining.
What specific performance improvements were observed?
Poetiq reported gains across every model tested. The most dramatic improvement was on Gemini 3.1 Pro, which jumped from 78.6% to 90.9%—a 12.3 percentage point increase—surpassing the 88.8% score of Google's own Gemini 3 Deep Think, a specialized reasoning model. GPT 5.5 High rose from 89.6% to 93.9%, a gain of 4.3 points. Even models that already performed well saw consistent lifts. These results were achieved using a harness specifically optimized on Gemini 3.1 Pro, yet the harness proved effective across other models, confirming its model-agnostic nature. The Meta-System's recursive self-improvement process automatically found the best harness configuration, leading to these state-of-the-art scores.

What are the three LLM task categories Poetiq uses?
Poetiq frames LLM performance around three distinct challenges. Reasoning challenges are benchmarked using ARC-AGI, which tests abstract pattern recognition and logical deduction. Retrieval challenges are measured by Humanity's Last Exam (HLE), a dataset requiring vast knowledge recall and synthesis. Coding challenges, the focus of this work, blend reasoning and retrieval with generating specialized procedural logic. Among these, coding is the most commercially widespread application of AI today. By targeting each category separately, Poetiq develops tailored strategies—their Meta-System approach for coding proved especially effective, automatically producing a harness that significantly improved performance on LCB Pro without any model changes.
What is a harness and why does it matter?
In AI coding, a harness refers to the infrastructure that manages how a model interacts with a problem. It can include prompt templates, step-by-step decomposition, validation checks, and iterative refinement loops. A well-designed harness helps the model avoid common errors, use resources efficiently, and produce more accurate solutions. Poetiq's Meta-System automatically creates and optimizes this harness by treating it as a program to be improved recursively. This matters because it demonstrates that significant performance gains are possible without modifying the model itself—just by better framing the task. The harness is model-agnostic, meaning it works with any LLM, and it was validated across multiple systems, showing that the right external scaffolding can unlock hidden capabilities.
What were the three stated objectives of the coding initiative?
Poetiq's coding initiative had three clear goals. First, to prove that an intelligent harness can boost model efficacy without fine-tuning or special access to model weights. The results on LCB Pro confirm this, with all models improving. Second, to validate the Meta-System's capacity for recursive self-improvement—meaning the system can iteratively refine its own harness design based on performance feedback. The harness used was generated automatically and then improved through multiple cycles. Third, to demonstrate that the resulting harness is model-agnostic, applicable to any LLM without modification. Indeed, the same harness optimized on one model lifted scores across all tested. All three objectives were satisfied, marking a significant step toward more efficient and generalizable AI performance enhancement.
Related Articles
- New AI Algorithms Crack the Code of Large Language Model Interactions at Scale
- Health Tech Titans Diverge: Google's AI Coach vs. Whoop's Human Doctors
- Harnessing Agentic AI in Xcode 26.3: A New Era of Intelligent Coding
- 5 Ways Google Home Is Becoming Your Smarter Home Assistant
- Mastering Claude Opus 4.7 on Amazon Bedrock: A Complete Deployment Guide
- AWS 2026: Key Updates on Quick, Connect, and OpenAI Partnership – Q&A
- Gemma 4 on Docker Hub: Your Q&A Guide to the Next-Gen Lightweight AI Models
- 7 Key Features of GPT-5.5 in Microsoft Foundry for Enterprise AI